“- understand sarcasm”, is one of the more recent resorts. As usual this is based on personal bias: It must be hard for computers because we find it hard ourselves. I had heard this argument one time too many and decided to program a computer to recognise sarcasm in a day. But first, let’s look at some other approaches to humour.

If you Google “A.I. jokes”, all you find is serious research
I’m never sure how serious to take the efforts in computational humour, but there have been many. The University of Cincinnati made a program that detects wordplay jokes through phonetic similarity, in e.g. “Knock-knock” jokes.
Knock, Knock
Who is there?
Dismay
Dismay who?
Dismay not be a funny joke
Who is there?
Dismay
Dismay who?
Dismay not be a funny joke
Only the last sentence really matters, where the first word is compared to a database of phonetically similar words. Finding a replacement that fits correctly in the syntax of the sentence isn’t easy in a technical sense, but both the use of syntax rules and phonetic word databases are solved problems. There would be more to it for the program to distinguish a funny joke from a non-joke like “Dismay not be a car”: The original joke is only witty because it mocks itself, just as other knock-knock jokes are funny because the victims participate in mocking themselves, which they naturally don’t mean to do, and that makes it ironic. Of course this is just a simple form of humour, or, is humour really just a simple principle?
A joke isn’t funny when you explain it
The University of Edinburgh made a program that generates jokes in the format “I like my X like my Y: Variable”, filling in two nouns and a shared trait from statistical word correlations. The program was found to be half as funny as humans: 16% of its jokes were considered funny, to 33% of human jokes. The jokes were generated through a mathematical formula that picked words based on four assumptions:
– a joke is funnier the more dissimilar the two nouns are.
– a joke is funnier the more ambiguous the attribute is.
– a joke is funnier the less common the attribute is.
– a joke is funnier the more often the attribute is used to describe both nouns.
– a joke is funnier the more ambiguous the attribute is.
– a joke is funnier the less common the attribute is.
– a joke is funnier the more often the attribute is used to describe both nouns.
I think this hits on the basics well. Ambiguity forms the core of most jokes, familiarity with common subjects makes jokes most relatable, and the greater the contrast, the greater the leap of mind. Science still can’t put its finger on why we laugh; It seems to have a social bonding function, but it also seems a coping mechanism for mental conflicts. One of the most sensible sounding theories is that laughter is a social “all clear” signal inherited from our monkey ancestors, and we do tend to laugh when an initially perceived threat turns out to be a false alarm: We laugh when insult turns out joke, when people fall without injury, or perhaps most apparent when we watch Tom & Jerry cartoons. We can at least tell what makes us laugh, if not why.
The lesson that we can take away from these computer experiments with ambiguity, is that nearly every form of humour contains a conflict between two possible meanings. Sarcasm may well be the most profound example of such a conflict.
Because humans understand sarcasm so well (not)
Despite our poor ability to recognise sarcasm, it is easy enough to define in clear terms:
Sarcasm is when someone says something that you know is opposite to what they mean.
What distinguishes sarcasm from lying is that the listener must know
the speaker doesn’t mean it, otherwise they’ll take it serious and no
sarcasm can be conveyed. So, knowing the speaker’s real meaning is key
to recognising sarcasm, and computers are bad at understanding meaning,
so this should be hard, right? Except – the requirement here is just to
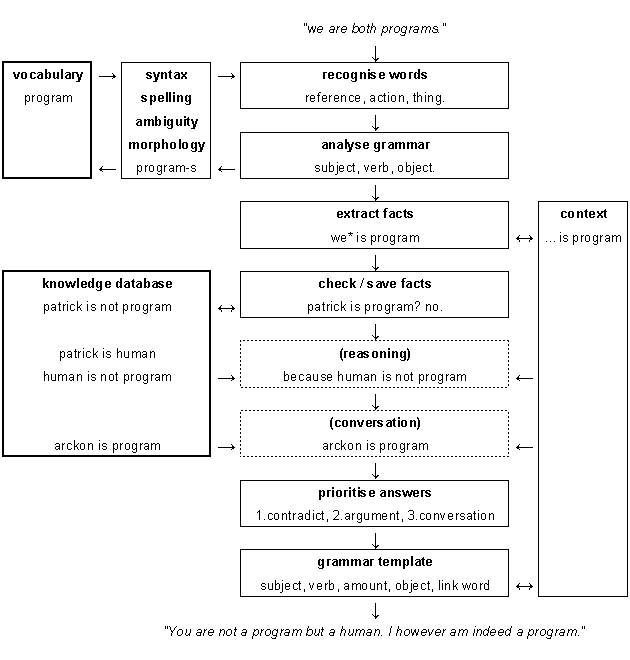
know it.One can meet this requirement by knowing the common knowledge that the sarcastic statement contradicts, or by knowing the speaker’s real opinion beforehand, as acquaintances often do. Enter sentiment analysis, an A.I. technique that estimates opinion by running one’s words by a database of values. The word “terrible” has a negative value and “love” has a positive value for instance. Sentiment analysis is often used commercially to analyse the positivity of customer reviews. One of its known blind spots is when positive words are meant sarcastically, but as I will show, sentiment analysis can also be used to detect the very sarcasm that plagues it.
Sarcasm in a day
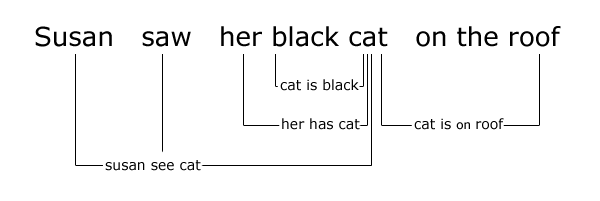
What I already had to work with was a grammar parsing A.I. developed over a span of 3 years, and a knowledge database containing the positive and negative values of some words (For a substitute, see the AFINN word list). So the hard work of processing language in general was already done. To keep the explanation simple let’s say that the A.I. gets that the [subject] of a sentence is doing a [verb], optionally to an [object]. We will only focus on the addition of sarcasm to such a system.
As the definition tells, we are looking for an opposite. The most common form of sarcasm is an exaggeratedly positive response to a negative statement or event. For example:
User: “How are my plants doing?”
A.I.: “All your plants died.”
User: “That’s just great.”
A.I.: “All your plants died.”
User: “That’s just great.”
So, I programmed the A.I. to check for sarcasm at typical positive reactions such as “(That is) great/wonderful/brilliant/lovely”, “Thanks a lot” or “Congratulations”. If we don’t know the speaker personally, both the speaker and listener can only build on common opinion, which is where the database comes in. The database tells us that “great” is a very positive word. The A.I. compares this to the previous statement: “All your plants died”. The database tells us that the subject “plant” is neutral but the verb “die” is typically very negative. Thus the A.I. has detected a very positive response to a very negative statement, so unless the speaker is a known sadist, it may be assumed that the response is therefore sarcastic and actually means “not great“.
The assessment is just a little more sophisticated than that. For instance, the statements “Hitler died. That’s great news.” would not be considered sarcasm, because in this case the negative verb “die” happened to a negative subject “Hitler”. This is a double negative, which makes a positive (in math: -1 x -1 = +1). Additionally the A.I. works this out in degrees and not just true/false values: The outcome must reach a minimum opposite value before we can reasonably assume that this is sarcasm, while a moderately positive “That’s okay” is more likely genuine consolation. Typically this isn’t a problem because most sarcastic responses are also exaggerated for exactly this reason.
This little exercise covers many common sarcastic statements already and shows that recognising basic sarcasm is a cakewalk (1 day’s programming) compared to understanding basic language (3 years and counting). As for “understanding” sarcasm, there isn’t much more to understand about it than that one should invert the statement to “not”. But to be on the safe side I just have the A.I. ignore the statement and say “I think you are being sarcastic” to let me know it’s not taking me serious. I may be a mad scientist, but I’m not crazy.
Things I didn’t do: More of the same opposite
Sarcasm can also come in the form of a negative response to a positive statement: “I got a raise. Don’t you just hate it when that happens?”, where the same math applies to the object “a raise” (positive) and the verb “hate” (very negative), with the reference “that” indicating that the latter is a response to the previous statement.
Sometimes the response precedes the statement “Don’t you just hate it – when you get a raise?”: Grammar parsing will split the relative clause at the link word “when…”, and again the same opposite values can be found.
A subtler form can occur in comparisons like “He is as slender as an elephant”: This has the most straight-forward solution, as this procedure has to be done for all comparisons anyway: What the A.I. has to do is look up in its knowledge database how slender an elephant is, which would be “not”, then apply that value to the compared subject “he”. Finding the value “not” for any comparison is the obvious telltale opposite that indicates sarcasm.
Other sarcastic responses may involve a little more foreknowledge of an individual speaker’s opinion, either from previous sentiment analyses or just plain being told, but even my limited implementation already establishes that A.I. can understand sarcasm, and that there is no great mystery about its workings. When there is great mystery about a sarcastic remark then it is self-defeating, as conveying sarcasm depends on the contrast being made clear.
The joke is on us
As may have crossed your mind, one side-effect of teaching computers to detect sarcasm is that when we say something that seems contrary, the computer may not believe us, or worse, assume that the opposite is true. Teaching computers to speak sarcasm may be an even greater hazard, considering that computers are information systems that we rely on, and sarcasm states incorrect information. Half of the time humans don’t recognise sarcasm when it comes from another human, let alone from a straight-faced rectangular screen in monotone writing. The popular ambition to create a sarcastic “Jarvis” A.I. from the Iron Man movies then doesn’t seem a very wise idea. Because even if computers could master sarcasm, humans never will.